
Quick links:
- Introduction
- Understanding the basic elements that affect your cost
- Designing an example cluster and calculating the cost
- Conclusion
Introduction
Elastic Cloud provides a simple way to build a cluster based on your needs using the hot/warm architecture. The challenging part is not the actual configuration and deployment of each of the nodes, but rather to wisely assign hardware specifications to your node tiers and choose the correct region/zone.
You can see a pricing table summary here. In this article we will review the different categories in the Elastic pricing calculator, and how each can impact your final cost.
Understanding the basic elements that affect your cost
1. Cloud Providers
You can choose from the following Cloud providers:
- Google cloud
- Amazon web services
- Azure
Elastic will handle all the underlying accounts and you will see no difference in the user experience. The difference between providers is the base machine templates that will be used. For example, you will see different disk-to-RAM ratios. Azure machines will have 60GB of RAM for data nodes, and GCP machines will have 64GB when you go beyond 60/64GB of capacity.
2. Region
You should pick the region that is closest to your clients in order to minimize the latency. Some regions support HTTPS connections only, but you should always be using HTTPS.
You can find the full list of regions here.
Zones incidents of each region
To see the historical uptime of a region, you can visit https://status.elastic.co/.
3. Hardware profile
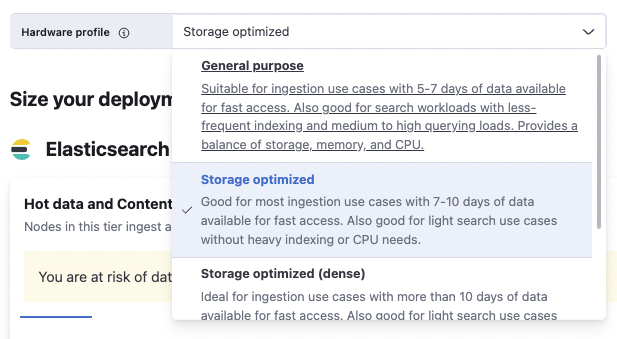
The hardware profile will define the disk-to-RAM ratio, and CPUs for the nodes. You may need to ingest a lot of documents, have a search intensive cluster, or just search through a small slice of your data and store the rest for a long time.
The available profiles are:
- General purpose: Balanced
- Storage optimized: Storage focused, high disk
- Storage optimized (dense): Storage focused, higher disk
- CPU optimized: High ingestion/high search concurrence, higher CPU
By following the above outline, your cluster will have enough RAM to handle your disk data, and enough CPUs for ingestion power/search concurrence. In reality it is more complex than the simplified version written here, but this is a good starting point.
4. Transfer and storage costs
There are also costs related to the data transfer and storage to keep in mind. The data that goes into the cluster is free, and then costs vary with data moving from the cluster to the outside, traveling from node to node within the cluster itself, and the storage space you use with the snapshots repository. You can find the full reference here.
Designing an example cluster and calculating the cost
Now that we understand the basics, we can start creating our cluster using the hot/warm architecture. You can read this article to fully dive into how it works.
After deciding on your hardware profile, you need to consider data retention and your ILM (Index Lifecycle) Policies, because these will define how much capacity each of your tiers will need.
For our example, we will assume the following specifications for our system:
- We have a time series logs system.
- The most common time filter is the last 7 days.
- Searching the last 30 days is also common, but less so than 7 days.
- Searches over more than 30 days are less frequent.
- 150 GB is ingested each day.
- Data retention is set to 1 year.
- Data needs high availability, fault tolerance and high search throughput on hot and warm zones.
We will choose the “Storage optimized” hardware profile because it is recommended for 7-10 days of fast access data.
Using the hot/warm architecture we can have 7 days of data in the hot zone, 23 days in the warm zone, and the rest of the data in the cold/frozen zone. This will match our requirement because the most common searches will hit the hot nodes, the less common will hit the warm nodes, and for anything older than 30 days we can sacrifice some of the performance in favor of better costs.
Choosing the correct number of shards is challenging and depends on a lot of factors. For simplicity we will set 1 primary, and 2 replicas. That way we can leverage the 3 availability zones for all of our indices.
Elastic will configure the nodes for you, so instead of specifying a number of nodes, you just need to specify the capacity you want, and Elastic will create the right number of nodes to handle that data. As we mentioned, there are slight differences from the different providers and hardware profiles, because each hardware profile matches with a provider instance type.
So for example, if you go beyond 64GB of RAM on a GCP provider for data nodes, each capacity increment step will be 64GB, and a new node will be added on each step.
There are different machine sizes for the different node types pre-configured to be aligned with the best practices. For example, dedicated master-eligible nodes will only be included if more than 6 data nodes are generated across the entire cluster, and the maximum amount of RAM assignable is 17GB per node. Kibana nodes are max 8GB of RAM, so if you set a capacity of 32GB, then 4 nodes will be generated.
If you click the info link, you can see the machine family, node roles and role attributes.
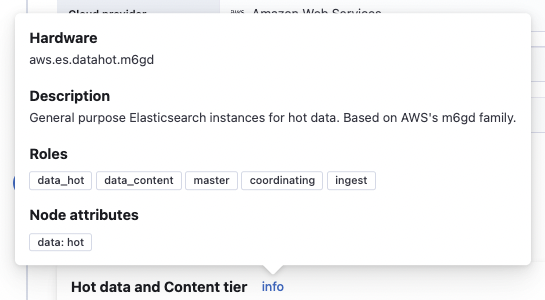
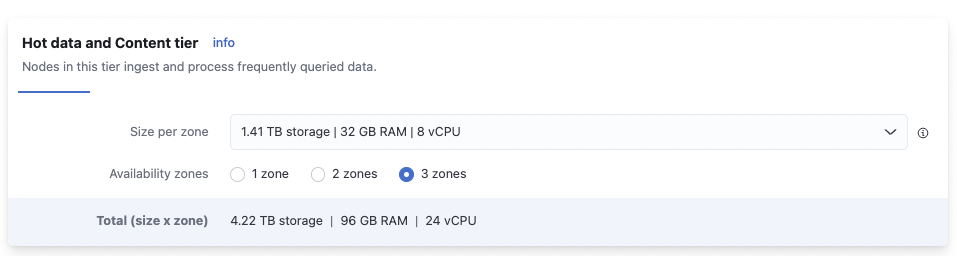
Hot data and content tier
Hot tier is where we will have the data we search the most. If you are using data streams, here is where the writing indices live. We will have the most powerful machines here, with the highest disk-to-RAM ratio, and the highest number of CPUs per RAM unit.
For our example of 7 days of hot data, and 150GB of data per day, we can safely choose 1.41TB, 32GB of RAM and 8vCPU. That will give us ~400GB room for growing space (~1.41TB – 7x150GB).
We set 3 zones because we want high availability. This setting will generate 3x32GB nodes.
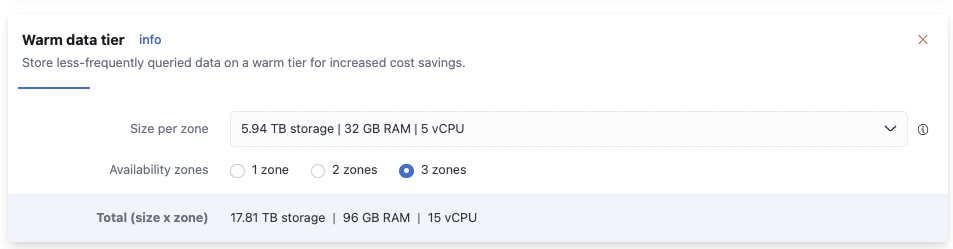
Warm data tier
Read-only and less searched data goes here. Per our requirements, we need to have 23 days of data here. This setting will generate 3x32GB nodes, 23 days of data would use 3.45TB so we have plenty of space to grow.
Cold/frozen data tier
We need to have the rest of the data here (323 days) so we need at least 48.45TB of disk space.
At this point we don’t care about the search speed like the other tiers because we are not searching this data frequently, perhaps only for an occasional report or an audit task, so it’s fine if the search results take a few seconds if that will save the company significant costs.
Cold and frozen tiers leverage snapshots, storing part of the data outside the Elastic cluster in a data repository like AWS S3 or GCP Cloud Storage, and mounting to the Elastic cluster when needed. This is called a searchable snapshot.
In the cold tier, you use your nodes to store the primary shards, and the replicas are stored in an object repository (S3 and similar), which is cheaper. If something happens with a node, the data will be recovered from the data repository which lives outside the cluster. This task is done by mounting a searchable snapshot, which is much faster than doing a full snapshot restore operation.
Frozen tier will use partially mounted indices. The most recent searches will be cached for fast access, and the rest of the data will live in a repository. If the searched data lives within the cache then the results will come as fast as a regular hot or warm node. If the data is not in cache, the data will be fetched from the repository and partially mounted in the cache.
Using cold or frozen will depend on prioritizing cost or speed. How much speed? That depends. There’s an Elastic blog post that benchmarks cold/frozen tiers and the results are pretty amazing.
“Return results from a simple term query over a 4TB dataset in just a couple of seconds if the data isn’t cached. If it’s cached, the performance is in the milliseconds — similar to the warm or cold tiers.”
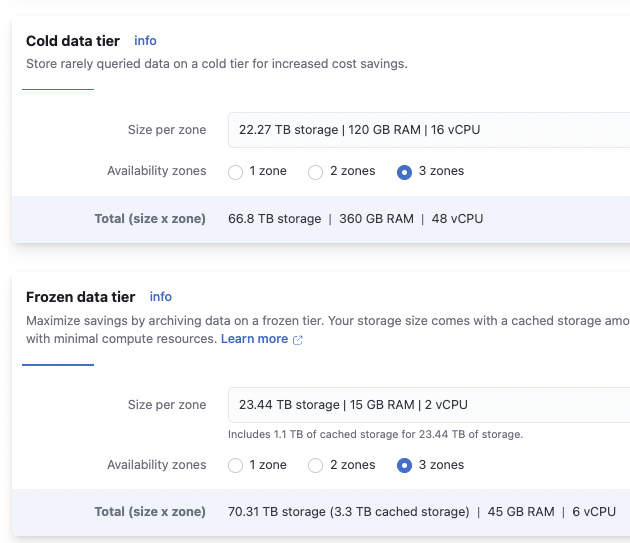
The cold data tier uses 8x of RAM and CPU to hold a similar volume of data than the frozen tier. The frozen tier is also much cheaper. This is because the cold tier is a fully mounted searchable snapshot index, and frozen tier is a partially mounted one. Only the cached data is mounted in the node.
We now can go ahead and create our deployment. Before sending any data in, you have to create the Index Lifecycle Policies (ILM) that will be aligned with this architecture.
Conclusion
The Elastic Pricing Calculator provides a convenient way to size your nodes according to your needs. You can apply best practices so you don’t have to worry about things like configuring JVM options, or disk-to-RAM ratios, as Elastic uses existing machine templates.
However, the challenge is to decide which part of the data will reside on each of the data tiers, depending on two relevant factors: performance and cost.