
Quick links
Introduction
Shard-level backpressure and search backpressure are two features of OpenSearch that seek to proactively improve cluster performance by selectively rejecting requests when the cluster is under stress. Let’s look at each in turn.
Shard indexing backpressure
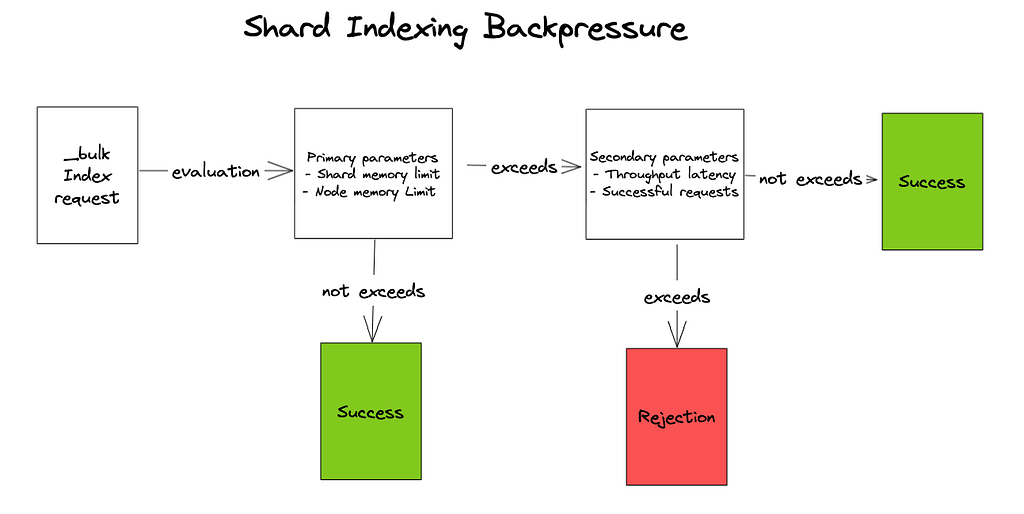
A big challenge when doing bulk indexing is to handle the rejections when the cluster is under stress. The default current system works with static memory limits and circuit breakers, which are reactive, and most of the time, it is too late to do something without facing system degradation.
Shard indexing backpressure is a smarter way of handling the load because it:
- Works at a shard level instead of a node level.
- Uses dynamic parameters that are re-calculated based on each shard load.
- Only affects involved shards, which means that the rest of the shards (especially those for unaffected indices) can keep receiving requests without downtime.
For shard indexing backpressure to occur, two limits must be breached, one within the “primary parameters” set and one within the “secondary parameters” set. It is only when one primary parameter and a secondary parameter exceed the limits that the request is rejected.
The Shard Indexing Pressure Memory Manager is a key component responsible for dynamically adjusting the allocated memory limits for shards based on incoming requests. A shard limit defines the maximum memory a shard can use in the heap for request objects.
The Memory Manager adapts shard limits according to the overall memory utilization on the node and the current traffic demands, ensuring optimal performance and resource allocation.
Primary parameters
- Shard memory limit breach: If the memory usage of a shard exceeds 95% of its allocated memory, this limit is breached.
- Node memory limit breach: If the memory usage of a node exceeds 70% of its allocated memory, this limit is breached.
If either of these parameters is breached, then the Shard Indexing Pressure Memory Manager will evaluate the secondary parameters.
Secondary parameters
If either of the following parameter thresholds is breached, then OpenSearch will reject the bulk request to the shard.
Throughput: If the throughput at the shard level decreases significantly compared to historic performance, then this threshold will be considered breached.
You can configure the window size and the degradation factor via settings.
Successful request: If the number of pending requests increases significantly compared to historic performance, then this threshold will be considered breached.
You can configure the amount of time a request can be pending and the number of outstanding requests via settings.
You can define a request size window to compare with the actual performance to determine if that performance is good or not. The size of the window and the evaluation criteria can be configured via dynamic cluster settings.
How to activate shard indexing backpressure
Shard indexing backpressure is disabled by default. You can activate it and adjust the settings that define how the parameters are evaluated using cluster settings.
The following command enables shard indexing and sets the parameters (in this example, the values used are defaults).
PUT _cluster/settings
{
"persistent": {
"shard_indexing_pressure": {
"enabled": true,
"enforced": true,
"primary_parameter": {
"node": {
"soft_limit": 0.7
},
"shard": {
"min_limit": 0.001
}
},
"operating_factor": {
"lower": 0.7,
"optimal": 0.85,
"upper": 0.95
},
"secondary_parameter": {
"throughput": {
"request_size_window": 2000,
"degradation_factor": 5
},
"successful_request": {
"elapsed_timeout": "300000ms",
"max_outstanding_requests": 100
}
}
}
}
}Definitions
High-level settings
“enabled”: true
This setting enables the feature.
“enforced”: true
When this is set to false, the feature will only track the backpressure stats but not reject any requests.
Primary parameters
“primary_parameter.node.soft_limit”: 0.7
This determines the maximum proportion of RAM the node can use before this parameter is considered breached.
“primary_parameter.shard.min_limit”: 0.001
This is the base RAM usage for a shard, which will be initialized as 1/1000th bytes of the node limit. This quota will be dynamically modified by the cluster based on its traffic to the shard.
Shard operating parameters
“operating_factor.lower”: 0.7
If shard utilization falls below 70% of the current shard limit, the Memory Manager may decrease the shard limit.
“operating_factor.optimal”: 0.85
The Memory Manager aims to update the shard limit to maintain shard utilization within the optimal range, which is around 85% of the current shard limit.
“operating_factor.upper”: 0.95
If shard utilization exceeds 95% of the current shard limit, the Memory Manager may increase the shard limit.
Secondary parameters
“secondary_parameter.throughput.request_size_window”: 2000
This is the number of requests used to calculate the average performance. Appropriate action will be taken once the result of this comparison exceeds the predetermined threshold value.
“secondary_parameter.throughput.degradation_factor”: 5
This factor defines how many times latency must increase to be considered a breach.
“secondary_parameter.successful_request.elapsed_timeout”: “300000ms”
This parameter establishes the maximum time that has passed since a request was last processed successfully.
“secondary_parameter.successful_request.max_outstanding_requests”: 100
This parameter defines the maximum number of outstanding requests that are still pending successful processing.
Stats API
To see the current status of the shard indexing backpressure, you can use the following command:
GET _nodes/_local/stats/shard_indexing_pressure?include_all
And if you only want to see the top-level aggregations, use the following command:
GET _nodes/_local/stats/shard_indexing_pressure?top
Now, let’s ingest some documents and check the API results:
POST _bulk
{ "index" : { "_index" : "myindex", "_id" : "1" } }
{ "field1" : "value" }
{ "index" : { "_index" : "myindex", "_id" : "2" } }
{ "field1" : "value" }
{ "index" : { "_index" : "myindex", "_id" : "3" } }
{ "field1" : "value" }
{ "index" : { "_index" : "myindex", "_id" : "4" } }
{ "field1" : "value" }
{ "index" : { "_index" : "myindex", "_id" : "5" } }
{ "field1" : "value" }
{ "index" : { "_index" : "myindex", "_id" : "6" } }
{ "field1" : "value" }Next, run the following:
GET _nodes/_local/stats/shard_indexing_pressure?include_all

Some of the stats are only visible when a bulk indexing task is active, but here you can see the last successful request time and the shard memory limit. Both stats are used to calculate the primary and secondary parameters and decide whether to reject a request or not.
Search backpressure
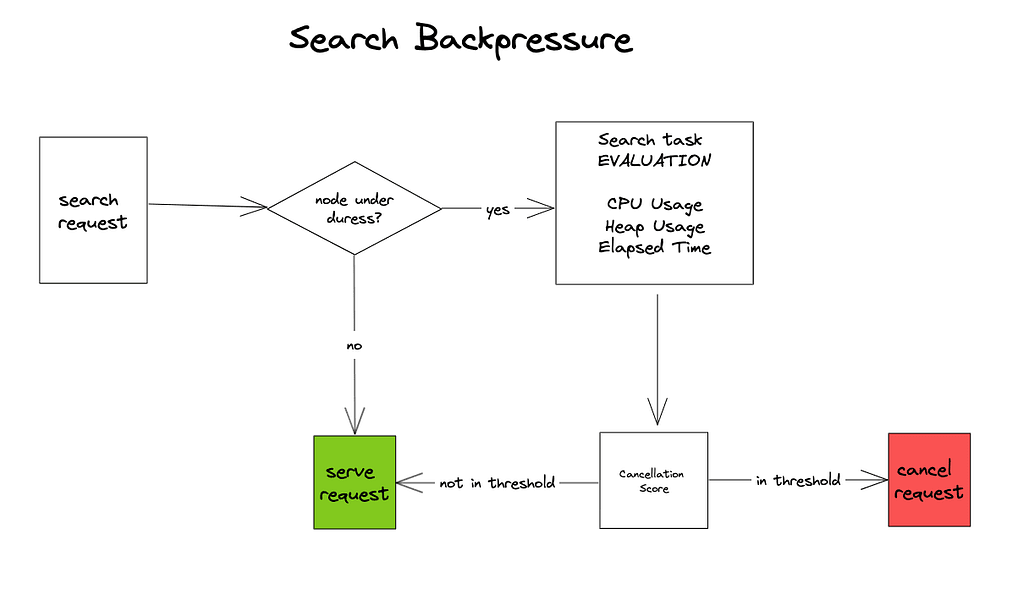
The goal of search backpressure is the same as indexing backpressure:
- Improve system stability by canceling requests before circuit breakers to avoid cascade failures
- Identify expensive queries to provide rejection fairness and only cancel heavy requests so the light ones can still be executed
- Provide an interface that allows users to see potential problematic queries in a granular way.
Its implementation, however, is a bit different. First, OpenSearch monitors each node to determine whether it is under duress based on heap, CPU, and successive breaches criteria.
Secondly, if the node is considered under duress, each search task is analyzed and a cancellation score is assigned. After that, a highly customizable process is triggered that will define which of the search tasks are considered candidates to be canceled.
This process is highly configurable, so you can modify the criteria that OpenSearch uses to determine if the node is under duress and also the basis upon which search tasks are canceled.
OpenSearch will continue classifying and canceling tasks until the node is no longer under duress.
Usage
By default, search backpressure runs in monitor_only, which will evaluate the search tasks and record stats but will not execute any cancellation. The enforced mode will actively cancel tasks. In the example below, we will enable the feature, apply all the settings with their default values, and explain each of them.
Note: This configuration was made using OpenSearch 2.6.0, which has different names for some of the settings compared to older versions.
PUT _cluster/settings
{
"persistent": {
"search_backpressure": {
"mode": "enforced",
"node_duress": {
"cpu_threshold": "0.9",
"heap_threshold": "0.7",
"num_successive_breaches": "3"
},
"search_task": {
"elapsed_time_millis_threshold": "45000",
"heap_variance": "2.0",
"heap_percent_threshold": "0.02",
"cancellation_burst": "5.0",
"cpu_time_millis_threshold": "30000",
"cancellation_ratio": "0.1",
"cancellation_rate": "0.003",
"total_heap_percent_threshold": "0.05",
"heap_moving_average_window_size": "100"
},
"search_shard_task": {
"elapsed_time_millis_threshold": "30000",
"heap_variance": "2.0",
"heap_percent_threshold": "0.005",
"cancellation_burst": "10.0",
"cpu_time_millis_threshold": "15000",
"cancellation_ratio": "0.1",
"cancellation_rate": "0.003",
"total_heap_percent_threshold": "0.05",
"heap_moving_average_window_size": "100"
}
}
}
}High-level settings
“mode”: “enforced”
This enables the feature. You can set it to monitor_only to track stats or disable it to turn it off.
Node duress parameters
cpu_threshold
This is the CPU usage percentage required for a node to be considered to be under duress.
heap_threshold
The heap usage percentage required for a node to be considered to be under duress.
num_successive_breaches
The number of successive limit breaches for the node to be considered under duress.
Search task parameters (by task or by shard)
Elapsed_time_millis_threshold
This is the time considered for a parent task or shard task to be considered for cancellation.
heap_variance
For search tasks: A task is considered for cancellation when taskHeapUsage is greater than or equal to heapUsageMovingAverage * variance.
For shard search tasks: The minimum variance required for a single search shard task’s heap usage compared to the rolling average of previously completed tasks before it is considered for cancellation.
heap_percent_threshold
The minimum heap percentage threshold for a parent task or a shard task to be considered for cancellation.
cancellation_burst
The maximum number of search tasks or shard search tasks to cancel in a single iteration of the observer thread.
cpu_time_millis_threshold
The minimum CPU usage threshold in milliseconds for a parent task or shard task to be considered for cancelation
cancellation_ratio
The ratio of the successful parent or shard search tasks to be eligible for cancellation. The value is calculated as a percentage of the successfully completed tasks.
cancellation_rate
The maximum number of tasks to be canceled per millisecond.
total_heap_percent_threshold
The heap percentage threshold for the sum of heap usages of all parent tasks or shard tasks to be considered for cancellation.
heap_moving_average_window_size
The number of previously completed tasks to consider when calculating the rolling average of heap usage.
Stats API
To see the current status of the search backpressure, you can use the following command:
GET _nodes/stats/search_backpressure
This API will return stats about parent search tasks, shard search tasks, CPU, heap usage, and a time tracker:
"search_backpressure": {
"search_task": {
"resource_tracker_stats": {
"cpu_usage_tracker": {
"cancellation_count": 0,
"current_max_millis": 0,
"current_avg_millis": 0
},
"elapsed_time_tracker": {
"cancellation_count": 0,
"current_max_millis": 0,
"current_avg_millis": 0
},
"heap_usage_tracker": {
"cancellation_count": 0,
"current_max_bytes": 0,
"current_avg_bytes": 0,
"rolling_avg_bytes": 0
}
},
"cancellation_stats": {
"cancellation_count": 0,
"cancellation_limit_reached_count": 0
}
},
"search_shard_task": {
"resource_tracker_stats": {
"cpu_usage_tracker": {
"cancellation_count": 0,
"current_max_millis": 0,
"current_avg_millis": 0
},
"elapsed_time_tracker": {
"cancellation_count": 0,
"current_max_millis": 0,
"current_avg_millis": 0
},
"heap_usage_tracker": {
"cancellation_count": 0,
"current_max_bytes": 0,
"current_avg_bytes": 0,
"rolling_avg_bytes": 0
}
},
"cancellation_stats": {
"cancellation_count": 0,
"cancellation_limit_reached_count": 0
}
},
"mode": "enforced"
}You can read a more detailed description of each of the response fields here.
Conclusion
Shard indexing backpressure and search backpressure in OpenSearch offer effective solutions to improve system stability during bulk indexing and search operations. These features work proactively to prevent circuit-breaker-related failures by identifying and canceling expensive requests while maintaining the execution of lighter requests.
Shard indexing backpressure operates at the shard level with dynamically calculated parameters, ensuring fairness by only affecting involved shards. It requires both primary and secondary parameters to be breached for a request to be rejected. The Shard Indexing Pressure Memory Manager plays a crucial role in adjusting memory limits for shards based on incoming requests and overall memory utilization on the node.
Search backpressure, on the other hand, monitors the node’s duress based on heap, CPU, and successive breaches criteria. When the node is under duress, search tasks are analyzed and a cancellation score is assigned. A highly customizable process then identifies which search tasks should be canceled.
Both the shard indexing backpressure and search backpressure features provide users with configurable settings and useful APIs to monitor system performance and manage resource allocation more effectively. Implementing these features can significantly enhance system stability and optimize resource usage during intensive indexing and search operations in OpenSearch.