
Quick links
Introduction
Over time we’ve seen that some of the Elasticsearch functions remain the same in OpenSearch, while others have begun to change. This is mainly because of the X-Pack features in Elasticsearch, so OpenSearch began to take its own path.
One of these features is how to manage the lifecycle of the indices across the cluster, and when to delete them. This is commonly known as Data Retention, but Elasticsearch and OpenSearch go one step further, also defining where the data should go before being deleted.
Elasticsearch calls it ILM (Index Lifecycle Management), and OpenSearch calls it ISM (Index State Management). The goal in both is the same, but we will see that the execution is different.
Watch the video below on the importance of setting up ILM/ISM in your deployment.

We will first compare the similarities, differences, and then we will create a simple hot-warm-delete state configuration in OpenSearch.
Similarities between ILM and ISM
- Both ILM and ISM work based on rolled over indices (Data Streams make this job easier).
- Indices can be moved based on index age, size, or number of documents.
- Both support shrinking, merge segments, changing of replicas, close index, index priority, read only, allocation and snapshot.
Differences between ILM and ISM
- In OpenSearch, hot/warm node types are configured as node attributes (this is true also for older Elasticsearch versions). Currently in Elasticsearch, hot/warm node types are configured as node roles.
- Elasticsearch ILM comes with hot/warm/cold/frozen/delete phases defined out of the box. In OpenSearch, the burden of creating and naming the phases is on you.
- OpenSearch exposes actions, states and transitions that you have to configure in the ISM configuration. Elasticsearch requires phases and actions within each phase.
- OpenSearch ISM supports notifications by Slack, Email, Chime, etc, for each of the phase transitions and errors, which can induce alert fatigue if not properly configured. In Elasticsearch, all ILM phase and action outcomes are stored in an index that can be leveraged like any other index to set up alerts.
- By default, OpenSearch runs ISM jobs every five minutes and Elasticsearch every ten minutes, but that interval is configurable in both solutions.
- Since release 8.11, Elasticsearch provides a new native and resilient lifecycle implementation for data streams that is much simpler to set up than both ILM and ISM.
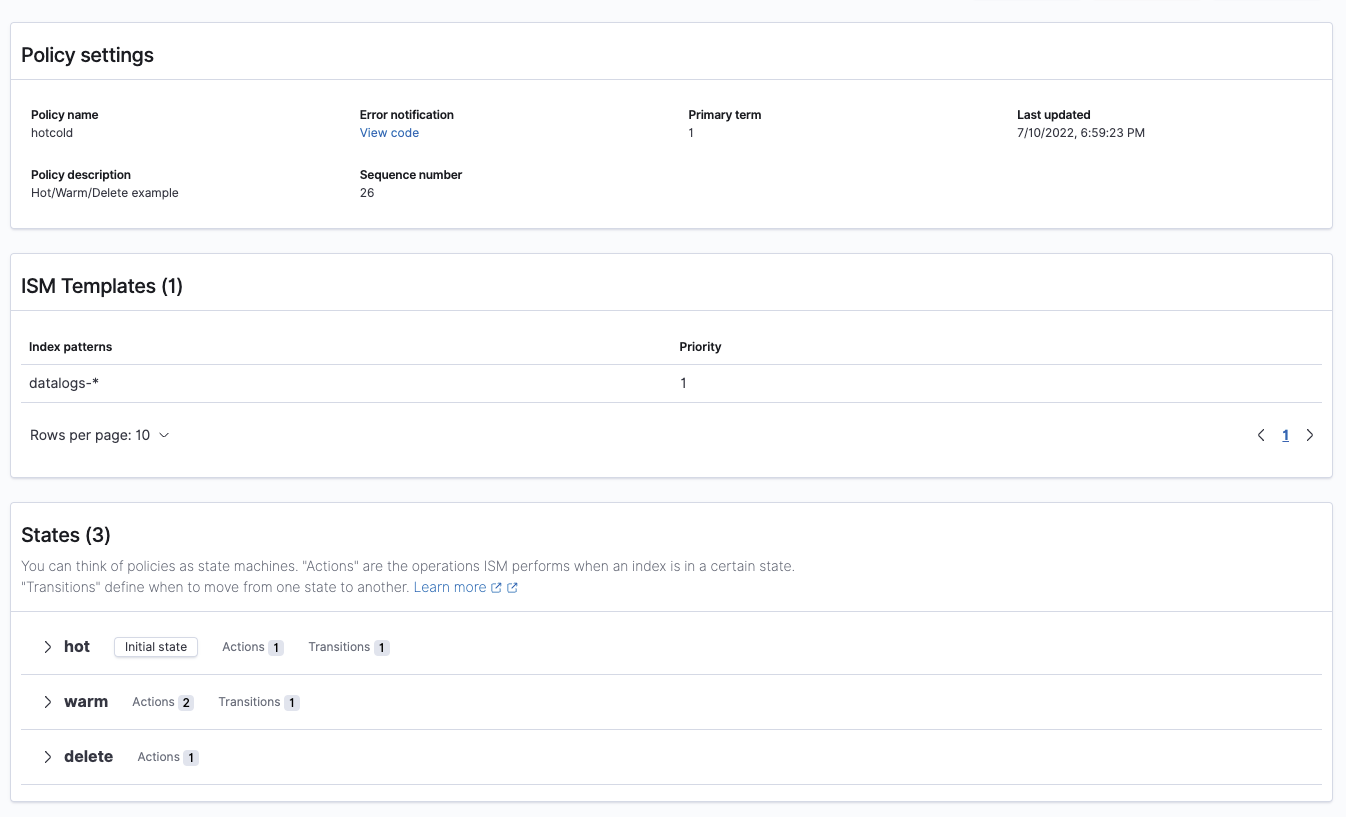
Creating an ISM Policy
We will create a policy with the following requirements:
- Rollover the index after 30 days or 50gb primary shard size to avoid oversharding the index.
- Stay in the hot zone for 7 days.
- Move to the warm zone, reduce replicas to 0 and stay there for 15 days.
- Delete and notify via email when the index was deleted.
We will use the datalogs-* pattern we created in the Data Streams article.
Run the following in Dev Tools to have the policy created. Make sure to replace the notification channel IDs with your own channels. For instructions on how to create your own notification channels, follow this guide. You can also refer to the channel creation docs here.
PUT _plugins/_ism/policies/example_hwd
{
"policy": {
"description": "Hot/Warm/Delete example",
"schema_version": 1,
"error_notification": {
"channel": {
"id": "tmHzgYEB62Ttjfftxmj-"
},
"message_template": {
"source": "Index {{ctx.index}} failed",
"lang": "mustache"
}
},
"default_state": "hot",
"states": [
{
"name": "hot",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"rollover": {
"min_index_age": "30d",
"min_primary_shard_size": "50gb"
}
}
],
"transitions": [
{
"state_name": "warm",
"conditions": {
"min_rollover_age": "7d"
}
}
]
},
{
"name": "warm",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"replica_count": {
"number_of_replicas": 0
}
}
],
"transitions": [
{
"state_name": "delete",
"conditions": {
"min_rollover_age": "15d"
}
}
]
},
{
"name": "delete",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"notification": {
"channel": {
"id": "tmHzgYEB62Ttjfftxmj-"
},
"message_template": {
"source": "Index: {{ctx.index}} Deleted",
"lang": "mustache"
}
}
}
],
"transitions": []
}
],
"ism_template": [
{
"index_patterns": [
"datalogs-*"
],
"priority": 100
}
]
}
}You can edit it visually by going to “Index policies” under “Index Management” in the left menu.
Notes and good things to know
Each data stream can only have one ISM policy, so it will fail if two policies with the same priority affect the same indices/data streams. Priority was increased to 100 to avoid collisions.
Also note that we are assuming all nodes are equal in terms of hardware, so we don’t really care about allocating our data in different nodes when moving shards from one phase to another (e.g: hot to warm).
In this article we review how to build the architecture to support shard allocation in our ISM policy. In this way, we can use our hardware efficiently and save costs with the least possible impact, moving the more active data to the fastest hardware, and the least searched one to the slower hardware.
Conclusion
Both Elasticsearch with ILM and OpenSearch with ISM offer simple ways to handle our indices’ data over time. We can move data across nodes to save costs, and move the oldest data to the cheapest hardware by configuring the most rigorous retention policies. With both tools we just have the initial configuration steps, and then the engine will take care of moving the data around.
OpenSearch integrated alerts within the ISM policies, which can be useful when used properly and sparingly. Elasticsearch made some good progress on formalizing the hot-warm infrastructure, creating specific node types for it, and from release 8.11 onwards, the new Data Stream Lifecycle feature makes it a breeze to configure your data lifecycle management inside Elasticsearch. We should be seeing more new features in both tools to make this process smoother and more efficient every day.