
Quick links
- Introduction
- Global ordinals
- Terms aggregation execution modes
- Refresh interval
- Choosing the best settings
Introduction
Terms aggregation is probably the most common aggregation type used in Elasticsearch. It helps us group our documents by a field value and obtain the document count of each of these values.
For low-cardinality fields (i.e., fields with a low amount of unique values), defaults will work just fine. But in some cases, you want to aggregate on high-cardinality fields, and some settings can be tweaked to improve the performance of the queries.
This article explains how to get the best out of terms aggregation for high-cardinality fields. But to understand how that works, it is first necessary to look at the role of global ordinals in Elasticsearch.
Global ordinals
To optimize terms aggregation, Elasticsearch uses a special structure called global ordinals, which collects the ordinal mappings from all the individual segments into a shared structure.
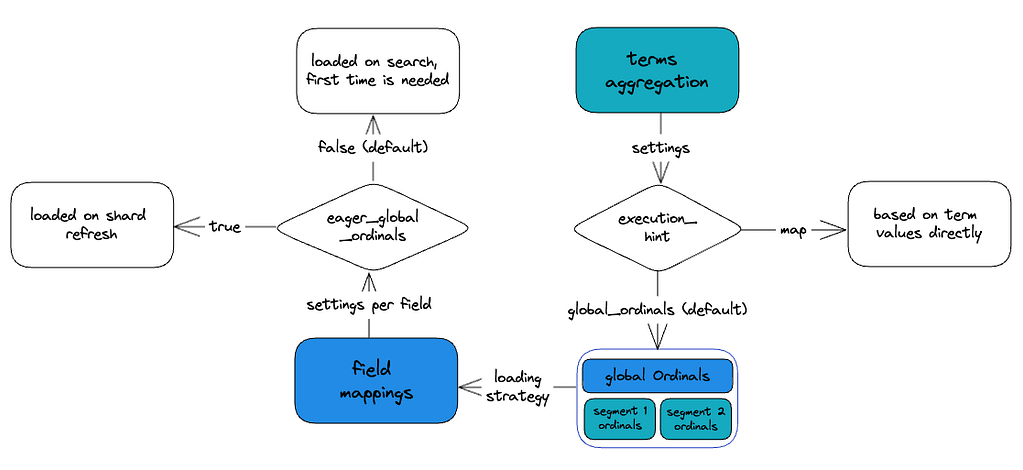
Loading global ordinals
The loading mode of global ordinals can be set on a per-field basis in the mappings via the eager_global_ordinals setting:
PUT my-index/_mapping
{
"properties": {
"some_field": {
"type": "keyword",
"eager_global_ordinals": false
}
}
}By default, global ordinals will be built the first time they are needed, which is optimal for indexing speed. However, if searching is a priority, then it’s recommended to set eager_global_ordinals to true.
Enabling eager_global_ordinals will build the global ordinals on index time every time a shard is refreshed.
Terms aggregation execution modes
Understanding the execution modes of terms aggregation is essential to appreciate the intricacies of the optimization process. Two execution modes are available under the “execution_hint” setting:
GET /_search
{
"aggs": {
"some_agg": {
"terms": {
"field": "some_field",
"execution_hint": "global_ordinals"
}
}
}
}The default method (global_ordinals) leverages global ordinals whereby each unique term’s ordinal table is computed per shard.
The alternate method employs “map”, where the terms are aggregated directly in memory. This setting will compute the aggregations only on the filtered documents, which is ideal if the queries you are running are restrictive (i.e., returning a small number of results) as global_ordinals will compute on all shards regardless of the query.
This computation occurs either at search time before running the filter phase (if eager_global_ordinals is set to false in the field mapping, which is the default) or at indexing time when the index is refreshed (if eager_global_ordinals is set to true in the field mapping).
Refresh interval
With the refresh_interval setting, you can delay how frequently the shard is refreshed (the default is 1 second), which delays the global ordinals re-building as well. This could be beneficial for high-cardinality field aggregations and when having the data updated to near-real-time is not critical.
Choosing the best settings
The cardinality of a field directly influences the time it takes to construct the global ordinal tables for that field’s values. Higher cardinality equals longer computation time. If the index is updated and refreshed frequently, the global ordinal tables will be computed at every refresh. This process can be time-consuming, particularly for high-cardinality fields. For read-only indices (such as older indices on time series data), this problem doesn’t exist because the shards are never refreshed, and the global ordinals table doesn’t need to be recomputed.
The scenario with heavy-write indexes presents a unique set of challenges. While there are no perfect solutions, several strategies can be employed to mitigate those challenges:
- For both low- and high-cardinality fields, a combination of the settings ‘eager_global_ordinals: true’ (to compute global ordinals at indexing time) and ‘refresh_interval: 1m’ (a value significantly higher than 1s to reduce the number of refreshes at indexing time) can produce satisfactory results, provided the data doesn’t need to be up-to-the-second fresh.
- For low- to high-cardinality fields coupled with fairly restrictive queries, using ‘execution_hint: map’ to prevent the computation of global ordinals can also be beneficial. However, this strategy depends on the use case and requires ample heap memory.
An advantage of the latter method is that the terms aggregation will only run on the filtered document set, which is not the case with global ordinals.
The advice given here is summarized in the following decision chart*:
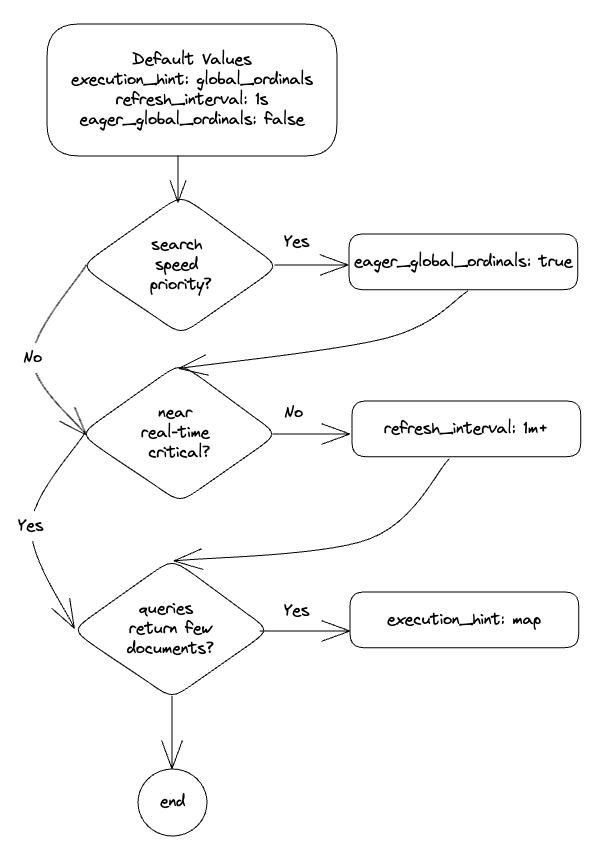
*The starting point is default values; every “Yes” will set that particular setting, and every “No” will keep the default value.