
Quick links
Definition
The order of the documents returned by Elasticsearch is determined by a score, which is a measure of how well a document matches a specific search. To calculate this score Elasticsearch uses an algorithm, the BM25, as described below. The Explain API is very useful for trying to understand why any particular document got a specific score. In this guide we will go through a few examples to demonstrate how and why documents get a particular score.
The BM25 algorithm
The BM25 algorithm is the default algorithm for scoring in Elasticsearch.
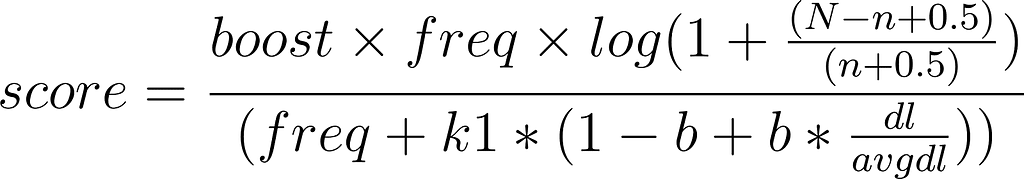
- `boost` – constant 2.2 = (k1 + 1), ignore, not relevant for ordering.
- `freq` – the number of times this term appears in the field.
- `k1` – constant 1.2, term saturation parameter, can be changed.
- `b` – constant 0.75, length normalization parameter, can be changed.
- `dl` – length of the field, specifically the number of terms in the field.
- `avgdl` – the average length of this field for every document in the cluster.
- `N` – the total number of documents in the index.
- `n` – the number of documents that contain this term.
Indexing documents
Let’s go through the Explain API using a couple example documents. In this case, we’re going to use a small list of movie quotes.
POST _bulk
{ "index" : { "_index" : "movie_quotes" } }
{ "title" : "The Incredibles", "quote": "Never look back, darling. It distracts from the now" }
{ "index" : { "_index" : "movie_quotes" } }
{ "title" : "The Lion King", "quote": "Oh yes, the past can hurt. But, you can either run from it or learn from it" }
{ "index" : { "_index" : "movie_quotes" } }
{ "title" : "Toy Story", "quote": "To infinity and beyond" }
{ "index" : { "_index" : "movie_quotes" } }
{ "title" : "Ratatouille", "quote": "You must not let anyone define your limits because of where you come from" }
{ "index" : { "_index" : "movie_quotes" } }
{ "title" : "Lilo and Stitch", "quote": "Ohana means family, family means nobody gets left behind. Or forgotten" }Example 1: Shorter fields are more important
Let’s run the Explain API:
GET movie_quotes/_search
{
"explain": true,
"query": {
"match": {
"quote": "the"
}
}
}We will get the following response:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.94581884,
"hits": [
{
"_shard": "[movie_quotes][0]",
"_node": "M9Dx5c1BTk6ehVVSCiJAvQ",
"_index": "movie_quotes",
"_id": "LMpi64YBn8MlrX4RQHf9",
"_score": 0.94581884,
"_source": {
"title": "The Incredibles",
"quote": "Never look back, darling. It distracts from the now"
},
"_explanation": {
"value": 0.94581884,
"description": "weight(quote:the in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.94581884,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 0.87546873,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 2,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 5,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.4910714,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1,
"description": "freq, occurrences of term within document",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 9,
"description": "dl, length of field",
"details": []
},
{
"value": 11,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
}
},
{
"_shard": "[movie_quotes][0]",
"_node": "M9Dx5c1BTk6ehVVSCiJAvQ",
"_index": "movie_quotes",
"_id": "Lcpi64YBn8MlrX4RQHf9",
"_score": 0.71575475,
"_source": {
"title": "The Lion King",
"quote": "Oh yes, the past can hurt. But, you can either run from it or learn from it"
},
"_explanation": {
"value": 0.71575475,
"description": "weight(quote:the in 1) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.71575475,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 0.87546873,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 2,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 5,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.3716216,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1,
"description": "freq, occurrences of term within document",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 17,
"description": "dl, length of field",
"details": []
},
{
"value": 11,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
}
}
]
}
}For the first document, The Incredibles, we arrive at the score `0.94581884,` by using the following calculation:
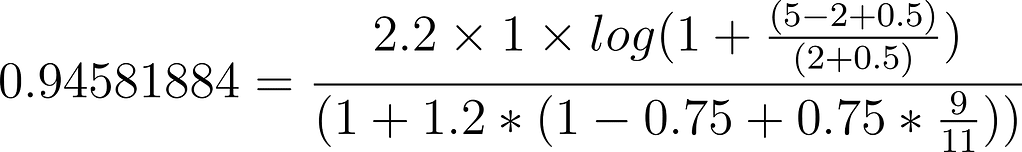
For the second document, The Lion King, we get `0.71575475,` which was calculated similarly as the equation above:
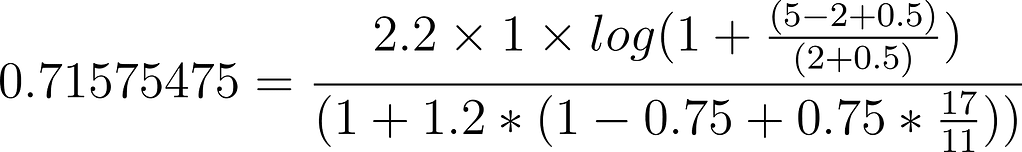
In this example the equation used is almost exactly the same, with the only difference being that in the second document, the field is 2 terms longer. The algorithm has been designed in a way that designates this document as less important because it has more terms. Why? Because the shorter the field that contains the term, the more real estate that’s been used for the term, so it must be more valuable.
Example 2: Higher term frequency in a field is more important
Let’s run the Explain API:
GET movie_quotes/_search
{
"explain": true,
"query": {
"match": {
"quote": "you"
}
}
}Skipping the full output this time for the document that came first, Ratatouille, we get a score of`1.1180129,` calculated as follows:
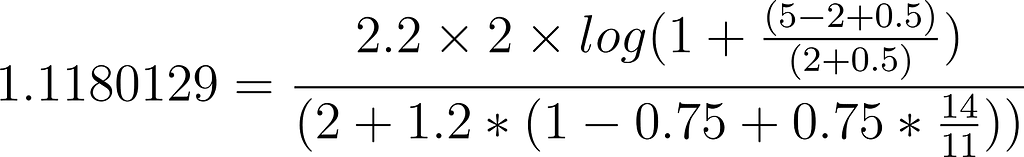
For the second document, The Lion King, we get `0.71575475,` calculated as follows:
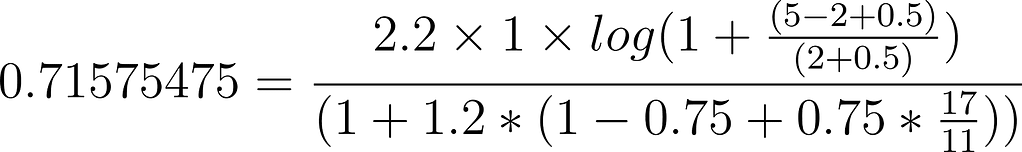
Once again, in this example the equation is very similar, however, the documents have very different scores, more so than the shorter field example. The differences now are in frequency and field length, the field length in the first document is shorter, and the term frequency is higher, the field length is important to a point, but the frequency is more important. Let’s look at another example to help us understand this point. We also see that the second document has the same score as the first document in the previous example. This is because the circumstances are the same, the same frequency and the same field length, and in this case, it’s actually the same document.
Example 3: Messing with the algorithm
Some might say, if term frequency is so important, can’t I just make sure my document always comes to the top by repeating the same term over and over? Let’s see what happens:
POST _bulk
{ "index" : { "_index" : "movie_quotes" } }
{ "title" : "Movie 1", "quote": "Movie movie movie movie." }
{ "index" : { "_index" : "movie_quotes" } }
{ "title" : "Movie 2", "quote": "Movie movie movie movie movie movie movie movie." }GET movie_quotes/_search
{
"explain": true,
"query": {
"match": {
"quote": "movie"
}
}
}For Movie 2, we get `2.2614799` and for Movie 1 we get `2.1889362.` These 2 scores are very similar, yet the reason that the `freq` is in the numerator and the denominator at first is because as the frequency of the term increases, the score boosts fast, but when the frequency gets to high, it becomes less and less relevant, even though the Movie 2 document has double the frequency of terms.
Conclusion
The examples provided here are short examples that utilized a simple match query, where the interplay of every possible condition has not yet been seen. However, this is a good starting point to really get to grips with the scores that documents receive and to understand how to start tuning documents to take advantage of this algorithm.
It is necessary to mention and understand at this point that the exact value of the score is irrelevant — the relative score is the only thing useful for ordering.
Notes and good things to know
- Really long fields that contain the term numerous times are less relevant than short fields with the term only a few times.
- Terms that appear in every document, bringing too many documents back, like the, an or a, also called stop words. This sample set is too small to really see how stop words can affect the number of documents returned.
- Since this is a movie database, you might find a completely new set of stop words specific to movies, like film, movie, flick, actor, camera and so on. With a larger movie database you will find that searching for some of these terms will bring back results that aren’t relevant.
- The complexity of the query increases as more parameters are added to the request, like searching for multiple terms in multiple fields, or looking for the same term in multiple fields, or looking for different terms in multiple fields.
- Begin exploring different query types from the Elasticsearch Query DSL, especially the Boolean Query, which really starts to bring out the power of relevancy tuning in Elasticsearch.